AWS Account Granularity
The growth of SPS Commerce has continued to be very strong, even amidst the recent global pandemic, as we work to provide an enabler for essential services. The demand for SPS services and products continues to grow and our architectural patterns additionally must continue to mature alongside of that demand growth. Like many organizations that started with a smaller footprint in the cloud that experienced exponential growth, part of our growing pain stems from the boundaries of our AWS Account structure. Having hundreds of engineers working across a single AWS Account for development simply doesn’t scale effectively. When we started in a single account for an environment, AWS was a lot less mature in the management capabilities of multiple AWS Accounts for a single Organization. If you are starting out fresh today, definitely heed their warning:
“A well-defined AWS account structure that your teams agree on will help you understand and optimize costs. As with tagging, it is important that you implement a deliberate account strategy early on and allow it to evolve in response to changing needs.” (AWS Documentation).
A few of the advantages of working with multiple accounts that are absolute requirements for continued maturity:
- Isolation of AWS Account Hard Resource Limits - It is very confining to start creating a new service only to realize that you have reached the maximum number of AWS API Gateway resources (100 per account?) or even the maximum number of Elastic Beanstalk Applications (30 per account?). AWS has been flexible at times to increase some of the resource limits in a pinch, but not by much. Engineering teams have structured and altered architectures to avoid usage of certain AWS Resources in the past because of these limitations. Moving to more refined accounts allows a team to entirely manage their own usage against some of these limits.
- Isolation of AWS Account Request Limits - Determining why your Lambda function is not executing when it should be can be very frustrating. Then you realize that your executions are getting starved because of rogue Lambda executions happening by another team’s service, taking all the executions based on AWS Account limits. More granular AWS Accounts again enables you to reduce any risk of noisy neighbors (even if those noisy neighbors are in your organization).
- Cost Allocation & Management by Account Simplified - SPS has always pushed a standardized tagging convention for AWS Resources from the beginning to effectively allocate costs to the right departments and teams. Even as such, there have long been some services that have not supported tags from initial creation, or other types of usage and traffic within the internal VPCs that go unallocated or are difficult to allocate. Using isolated AWS Accounts still allows for tagging conventions for more granularity, but also acts as a clear catch-all for everything else.
- Grouping of Resources for Management & Cleanup - Working in a single account, one of the initial conventions we introduced was that all delivery teams should compose and create their infrastructure in Cloud Formation stacks. A key aspect of this requirement was to enforce a clear understanding of what resources were grouped with each other, also enabling the capability to “clean up that stack”. In some cases, not all infrastructure fits into that CF stack, or perhaps you are not even using CF (i.e. Terraform). Loosening this restriction by allowing teams to own their AWS Accounts for managing resources reduces the risk of managing and cleaning up resources outside of Cloud Formation stacks.
- IAM Permissions for Engineers - SPS has always had a fairly flexible and self-service capability to manage IAM permissions in AWS backed by manager approval and audit workflows. That being said, it sometimes was not trivial to figure out some of the very granular permissions to apply to a team that needed a slice of functionality as to not affect or be capable of altering another team’s resource in production. Those permissions in a separate account now become a lot simpler and less restrictive, enabling easier debugging, and at the same time allowing for teams to move a bit faster with a bit more manual access in non-production environments to spike and test new architectures with direct AWS IAM access they may not have had before.
Managing multiple AWS Accounts inside AWS Organizations is well beyond the intent of this article. But recognizing the advantages of working in a multi-account organization and its eventual necessity is key. With that being said though, there is a primary difference to having a single shared AWS Account to build and deploy into, compared to building and deploying into multiple AWS Accounts. When you find yourself in this situation, the simplicity of writing IAM permissions in your single AWS Account for your application to have implicit access to everything it needs now suddenly becomes a lot more confusing and difficult to reason about when your application straddles multiple AWS Accounts. Additionally, reasoning aside, the complexities of infrastructure design begin leaking much more heavily into your codebases, wrapped together with business logic as specific AWS Account IDs, and ARNs start to pollute your code. In an effort to keep that leaking of infrastructure knowledge as far to the boundary of our app domain as possible, let us take a look at patterns we can use to work in an AWS multi-account world, with the day-to-day developer experience top of mind. I think you will find that there are a few generic options to enable and simplify cross-account access, but using IAM Role associated with EKS and Kubernetes Service Accounts is the cleanest, and really abstracts the cross-account leaks into the infrastructure.
Centralizing Compute
As SPS Engineering teams begin moving their AWS Resources to isolated team and product-based accounts, they are additionally moving container-based compute workloads in the opposite direction; that is to centralize our container workloads into a new platform built on-top of EKS and other AWS services. The reason SPS centralizes containerized compute is to both increase compute density in the clusters to lower costs, as well as to increase operational efficiency by operating far fewer compute clusters. Through internal custom deployment patterns and architecture, deploying containers to a cluster is relatively simple, alongside the deployment of AWS Resources using Cloud Formation to a different account. But the unanticipated complexity in dealing with cross-account AWS Resource access has caused some churn amongst our engineering teams as we work to standardize and “keep things simple” where possible. Definitely a luxury of an AWS single account world that is difficult to leave behind, but is absolutely necessary as mentioned above for growth and for security.
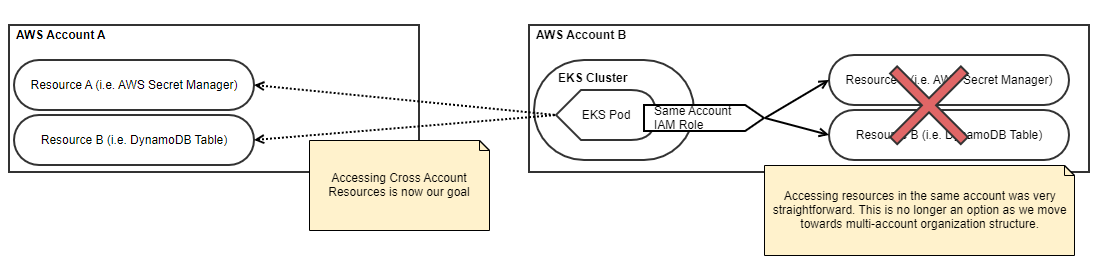
The below example should set up our scenario and where we need to migrate from; the standard setup of our two resources, followed by an IAM Role with access to the resources in the same account. Generally speaking, you would probably be more restrictive on wildcard usage, but this works well for demonstration and simplicity.
# CloudFormation AWS Resources we want to access
Resources:
AppDemoSecret:
Type: AWS::SecretsManager::Secret
Properties:
Name: AppDemoSecret
Description: AWS Secret Deployed via CFN
# KMS Key we have created and are resolving the ARN for
KmsKeyId: '{{resolve:ssm:/organizations/sip32/sip32-resources-v0-KeyARN:1}}'
AppDemoTable:
Type: AWS::DynamoDB::Table
Properties:
TableName: AppDemoTable
BillingMode: PAY_PER_REQUEST
AttributeDefinitions:
- AttributeName: "Code"
AttributeType: "S"
KeySchema:
- AttributeName: "Code"
KeyType: "HASH"
# CloudFormation - AWS IAM Role to enable our application to read resources.
AppRole:
Type: AWS::IAM::Role
Properties:
RoleName: AppRole
AssumeRolePolicyDocument:
Version: 2012-10-17
Statement:
- Effect: Allow
Principal:
Service: ec2.amazonaws.com
Action:
- sts:AssumeRole
Policies:
- PolicyName: SecretAccess
PolicyDocument:
Version: "2012-10-17"
Statement:
- Effect: Allow
Action:
- kms:Decrypt
Resource: *
- Effect: Allow
Action:
- secretsmanager:Describe*
- secretsmanager:GetSecretValue
Resource: *
- PolicyName: DynamoDBAccess
PolicyDocument:
Version: "2012-10-17"
Statement:
- Effect: Allow
Action:
- dynamodb:Get*
Resource: *
Cross Account Access Patterns
Role Assumption
The first obvious approach is to assume a different role that exists inside the new AWS Account where the resources are.
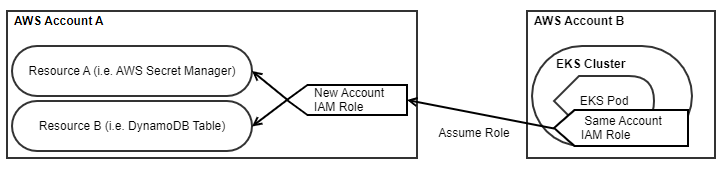
This has the implication of needing to create two IAM Roles, one in each account, with two different Cloud Formation stacks deployed to their respective accounts. The IAM Role created in Account B only has permissions to assume the role created in Account A. We have to provide an explicit “AssumeRolePolicyDocument” that gives the ability to assume this role from the other account.
# CloudFormation - AWS IAM Role in SAME ACCOUNT B
# this only has the ability to ASSUME the other Role
AppRole:
Type: AWS::IAM::Role
Properties:
RoleName: AppRole
AssumeRolePolicyDocument:
Version: 2012-10-17
Statement:
- Effect: Allow
Principal:
Service: ec2.amazonaws.com
Action:
- sts:AssumeRole
Policies:
- PolicyName: NewAccountRoleAccess
PolicyDocument:
Version: "2012-10-17"
Statement:
- Effect: Allow
Action:
- sts:AssumeRole
Resource: "arn:aws:iam::*:role/AppRole*"
# NOTE: THESE WOULD EXIST IN DIFFERENT CLOUD FORMATION
# TEMPLATES, DEPLOYED TO THEIR RESPECTIVE ACCOUNTS.
# CloudFormation - AWS IAM Role in NEW ACCOUNT A
# this has the ability to consume the resources
AppRole:
Type: AWS::IAM::Role
Properties:
RoleName: AppRole
AssumeRolePolicyDocument:
Version: 2012-10-17
Statement:
# CORE CHANGE FOR THE ROLE IN THE NEW ACCOUNT
# IS TO ALLOW IT BE ASSUMED FROM THE OLD ACCOUNT
# WARNING: Demonstration only, in production you'll want to
# provide more restrictive access than :root.
- Effect: Allow
Action:
- sts:AssumeRole
Principal:
AWS: !Sub
- 'arn:aws:iam::${AccountId}:root'
- { AccountId: 'YOUR-OLD-ACCOUNT-ID-HERE' }
Policies:
... SAME AS POLICIES FROM INITIAL EXAMPLE TO READ RESOURCES....
With permissions in place, your application must also be updated to support this capability to assume the new role as needed. Take a look at what this glue code might look like if we wanted to access and read a record from the Dynamo Table:
// **NEW** accessing the DynamoDB table in the other account we
// need to assume the role allowed in ACCOUNT A
// (this code is executing in ACCOUNT B inside the container).
Credentials creds;
using (var client = new AmazonSecurityTokenServiceClient())
{
var request = new AssumeRoleRequest
{
// THIS MUST BE THE FULL IAM ROLE ARN FROM ACCOUNT A
RoleArn = "arn:aws:iam::{AccountId}:role/AppRole",
// must be at least 900 (15 min ) but less than 1hr (3600 seconds MAX)
DurationSeconds = 900,
RoleSessionName = "RoleFromMyApp"
};
var result = await client.AssumeRoleAsync(request);
creds = result.Credentials;
}
// **SAME** normal access the dynamic DB table (this the same code,
// the only difference is padding in the assumed role credentials
// to the Amazon Dynamo DB Client)
using (var client = new AmazonDynamoDBClient(creds))
{
var response = await client.ScanAsync("AppDemoTable", new List { "Code" });
var item = response.Items.ToList().SingleOrDefault();
return $"Value from Dynamo: { item["Code"].S }";
}
In this contrived and simple example, you can see the code to assume the necessary role is more lines than the original code to just access the table directly in the same account. The duplicity of adding multiple roles, and having to assume the proper role before using a resource definitely adds a bit of pain and requires augmentation to any codebase moving to the multi-account world. In general, I think there are a series of small pain points that just don’t make this ideal:
- Creation of Multiple IAM Roles: It’s definitely not ideal, but the requirement of two different IAM roles, configured for role assumption from another account isn’t incredibly difficult. You’ll need to ensure you set up different cloud formation stacks (deploys) in each account respectively.
- Assuming the Role in Code - Having to assume the additional role in code is not great either. As you start to proliferate the pattern throughout your code, it seems unreasonable to think all engineering teams will do this or should do this. At the very least, for this pattern, I would abstract the role assumption into another “using” statement or dependency wrapper that can be centralized and shared amongst a set of reusable libraries.
- Assume Role Expiration - While you may be thinking that you could offload the role assumption to other infrastructure that could re-apply the role assumption temporary credentials to your container or compute, it becomes a lot more complex when you consider the expiration of the role assumption credentials. In the example above, it is set to expire after 15 min, with 1 hr being the max by default (configurable up to 12 hrs). As such, you’d have to have a process and service track and manage all the role assumption code, and this single tracking service that can assume any other role in another account might be too risky from a security standpoint. Continuing to handle the role assumption in your code means that you need a balance of re-assuming the role, but caching the credentials for a period of time. Again this logic might live in a reusable library for your ecosystem within the organization.
- Fragility in Gluing the ARNs - I strive in my deployment pipelines to make the dependency on deploy time configuration as little as possible. What I mean by this is trying to reduce the configuration of a dynamic IAM Role ARN in another account that was JUST created as part of the deployment is not ideal. This creates some level of dependency where I need to dynamically get that role ARN created during the deployment to add a configuration for my application to assume. Alternatively, I derive a conventional static name and use it in both Cloud Formation and the Application (not ideal for reasons of immutability, redeploy and resource uniqueness… but perhaps a better of two evils?).
- Security Implications - By default, when assuming a role and accessing resources in another AWS Account, the traffic is sent over the public internet. This may surprise you as you are not simply working inside your single account and VPC for AWS requests. This of course is highly undesirable for accessing secrets in AWS Secret Manager or SSM Parameter Store, for example. To mitigate this, teams typically use VPC Endpoint Policies to control the traffic for necessary AWS services. This is true whether you are working in a single AWS Account or many. It now becomes necessary to additionally set up VPC Endpoint Policies for each new account you have.
Assuming a cross-account role will definitely work. In fact, this is a great escape hatch and technique that may be necessary as you migrate to multiple AWS Accounts, or perhaps as you decompose an existing monolithic application and need to piece together more than one account or resource (i.e. assume different roles for different features), but it is not the destination we wanted to land on for our developer experience.
Resource Policies
Resource-based policies are a newer capability that natively supports the idea of accessing resources between accounts without having to assume a role. Resource-based policies are added to the resource you want to access and define explicitly who should have permission. This is different than the normal Identity-based policies, so be sure to review the differences. I think of Resource-based policies as being similar to the “AssumeRolePolicyDocument” for defining who can assume the role instead it just defines exactly who should have permissions to use it. Once you add a Resource policy to an AWS Resource, it then applies to both cross-account access as well as access within the same account too (interesting behavior that has uses for other security discussions as well). Much like the definition of any trust relationship, definitions in the Resource policy MUST NOT use any wildcarding, but rather full references to any ARNs including those wanting access from other accounts. These ARNs are also validated and will fail deployment if they do not exist. Resource policies have become very popular to give cross-account access (or even third-party access) for S3 buckets. AWS Secrets Manager is additionally often used with resource policies to share secrets in an organization with multiple accounts.
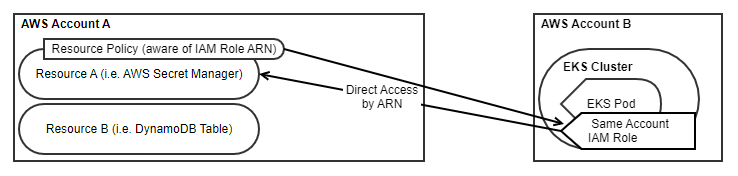
Let us take a look at with this does to our cloud formation templates. This time, we only need one IAM Role in Account B, but we’ll need to define a Resource policy on our AWS Secret Manager resource.
# CLOUD FORMATION RESOURCES - DEPLOYED TO ACCOUNT A
Resources:
AppDemoSecret:
Type: AWS::SecretsManager::Secret
Properties:
Name: AppDemoSecret
Description: AWS Secret Deployed via CFN
# KMS Key we have created and are resolving the ARN for
KmsKeyId: '{{resolve:ssm:/organizations/sip32/sip32-resources-v0-KeyARN:1}}'
AppDemoSecretResourcePolicy:
Type: AWS::SecretsManager::ResourcePolicy
Properties:
# Note: At this time you can only assign one Secret, making this
# policy NOT REUSEABLE, NOOOO :(
SecretId: !Ref 'AppDemoSecret'
ResourcePolicy:
Version: '2012-10-17'
Statement:
# allow access to this secret from our application deployed
# in the compute or legacy account.
- Effect: Allow
Principal:
AWS: !Sub
# # THIS MUST BE THE FULL IAM ROLE ARN (no wildcarding)
- 'arn:aws:iam::${AccountId}:role/AppRole'
- { AccountId: 'ACCOUNT-ID-FROM-ACCOUNT-B-TO-GIVE-ACCESS' }
Action:
- secretsmanager:Describe*
- secretsmanager:GetSecretValue
Resource: '*'
# CLOUD FORMATION APP ROLE - DEPLOYED TO ACCOUNT B
Resources:
AppRole:
Type: AWS::IAM::Role
Properties:
RoleName: AppRole
AssumeRolePolicyDocument:
Version: 2012-10-17
Statement:
- Effect: Allow
Principal:
Service: ec2.amazonaws.com
Action:
- sts:AssumeRole
Policies:
- PolicyName: SecretAccess
PolicyDocument:
Version: "2012-10-17"
Statement:
- Effect: Allow
Action:
- kms:Decrypt
Resource: *
- Effect: Allow
Action:
- secretsmanager:Describe*
- secretsmanager:GetSecretValue
Resource:
# SINCE THIS IS CROSS-ACCOUNT NOW, RESOURCE:* CANNOT BE USED.
# We have to be more explicit on the account / region.
# You can still use wildcard here without having the full ARN to the secret.
- !Sub
- 'arn:aws:secretsmanager:${AWS::Region}:${AccountId}:secret:AppDemoSecret*'
- { AccountId: 'ACCOUNT-ID-WHERE-SECRETS-EXIST' }
This would effectively enable us to now make a cross-account request to access an AWS Secret Manager value. The only difference in code that I need to make is to request the Secret by FULL ARN (super annoying, but obviously necessary in a multi-account world):
using (var client = new AmazonSecretsManagerClient())
{
var request = new GetSecretValueRequest();
// Use Full ARN For Cross-Account:
// "arn:aws:secretsmanager:us-east-1::secret:AppDemoSecret";
request.SecretId = "AppDemoSecret";
var secretValue = client.GetSecretValueAsync(request).Result;
}
You’ll notice that this effectively solves a couple of pieces of complexity surrounding the simplification of the code, and we only require one IAM role now. That being said, there are several caveats:
- Deployment Sequence Matters - Since the deployment of Resource Policies requires full ARNs that already exist, the order is very important. Identity-based policies allow for wildcarded ARNs making it possible to deploy the IAM Role to Account B, followed by deployment of the AWS Resources (secrets) to Account A. This is somewhat backward for how you’d expect to deploy dependencies of the app first (not last). It can make for difficult or awkward deployment scenarios.
- Requests with Full AWS ARNs for Resources - Unfortunately our code is NOT entirely agnostic of working with multiple AWS Accounts because we have to know to use the full AWS ARN to reference any cross-account resources. Not a huge deal, but definitely annoying if you plan to only ever work inside a single account for your resources. Your application now has to have configured contextual awareness for an AWS Account ID. Resource-based Policies are Explicit - Depending on your configuration, be aware that we only provided access for the secret above to the role in the other account. Even when working in Account A, I still don’t have permission to retrieve the secret unless I update the Resource policy to allow for that as well. This is very nice from a security auditing perspective as it is EXACTLY clear (without wildcards) who has access to a secret but makes your life a bit more difficult perhaps with some valuable friction (IAM policies using root access in the same account will still work).
- AWS Secret Manager Resource Policies Are Not Reusable - A very specific mention of this particular item seemed noteworthy. You’ll notice that a Secret Manager Resource Policy can only be assigned to a single Secret. This is very annoying as you must copy and paste the Resource Policy for every secret, and it cannot be shared (one to one).
- Resource-based Policy Support is Not Global - The real crux of using Resource Policies is that they are simply not available for every AWS Resource. In fact, notice for our example and the diagram above that I did not mention Dynamo DB or show how to set up a Resource policy for it. The reason is that Dynamo DB is an example AWS Resource that DOES NOT currently support Resource-based access policies. That puts a big damper on this option, knowing that realistically you’d have to combine this pattern with the role assumption pattern where necessary. You will want to dive in deeper to see what resources support Resource-based policies.
- Usage Limits - For the purposes of billing and throttling, requests to any AWS API are attributed to the account owning the IAM role under which the request is made. In our case, we want to centralize container compute into a single account. This means when using Resource policies that the recorded API requests for secrets (or other resources) will be centrally counted towards the single account B and not our AWS Resource Account A. Depending on the resource and its throttling limits this might render this pattern pretty ineffective to scale in the way we intend to without the risk of throttling (especially has services restart and pull secrets). Service Specific Limitations - At times there may be specific considerations for an AWS Service using Resource Policies. One of these examples would be using the default KMS Key from the AWS Account to create a secret in AWS Secret Manager. Since KMS aliases do not work across accounts, you’d be unable to decrypt the secret from another account if you originally created the secret with that alias.
While this pattern using Resource policies definitely can simplify some of your code, it certainly makes your Cloud Formation dramatically more complex in my opinion. The fact that you cannot use Resource policies for all AWS Resources and the caveat about usage limits make this pattern fall a bit short in some cases as a one-stop pattern for working with multiple accounts. It might just be preferable to use role assumption to enable full compatibility of all resources and standardize your pattern for access.
IAM Roles for Kubernetes Service Accounts
Sometimes it is easy to get blinded by the way you have always done things. It’s very engrained for us engineers working in AWS to consider how we associate IAM roles to Compute, assuming that compute is EC2 (definitely speaking about myself here!). If you are using EKS or ECS, you are automatically thinking about what the worker node permissions are and attempting to understand how you associate an IAM Role to it. Using EKS, an alternative exists to associate IAM roles directly to Kubernetes Service Accounts. This provides an entirely different offering for achieving our centralized compute with isolated AWS Accounts for AWS Resources. In fact, this capability provides a much more Kube native experience for associating granular permissions and IAM roles. Since this takes advantage of the AssumeRoleWithWebIdentity API part of STS, we can make use of this pattern regardless of the AWS Account we are in by setting up the Open ID Connect Providers on a per cluster basis. Find all the technical details for set up in the “IAM Roles for Service Accounts Technical Overview”.
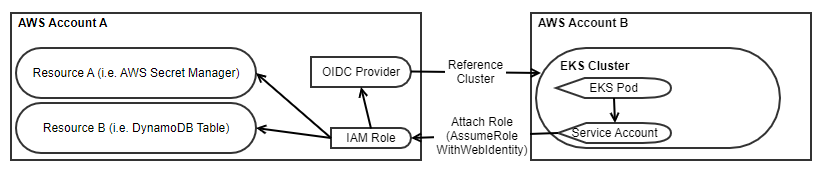
While you can clearly see in the provided walkthrough how to set up the provider, IAM Role, and Kube Service Account, the following is the only change we have that is necessary inside our Cloud Formation template. It is pretty close to the original scenario we started within a single account, with the one key difference in the Role “AssumeRolePolicyDocument”, giving access to the OIDC Provider to retrieve temporary credentials to assume the role. All the AWS Resources exist in AWS Account A, while all the Kube Resources exist in the cluster in AWS Account B.
The particulars of the OIDC Provider and the Kube Service Accounts are well explained in the technical documentation and have been intentionally left out here to focus on the day-to-day experience faced by an Engineering team adding a new service having to use multiple AWS Accounts.
Resources:
AppDemoSecret:
... NO DIFFERENT IN SECRET CREATION
AppDemoTable:
... NO DIFFERENT IN TABLE CREATION ...
AppRole:
Type: AWS::IAM::Role
Properties:
RoleName: AppRole
AssumeRolePolicyDocument:
Version: 2012-10-17
Statement:
- Effect: Allow
Principal:
Service: ec2.amazonaws.com
Action:
- sts:AssumeRole
# ALLOW THE OIDC PROVIDER CREATED TO ASSUME THIS ROLE
- Effect: Allow
Principal:
# ID Provided by the OIDC Provider
Federated: !Sub arn:aws:iam::${AWS::AccountId}:oidc-provider
/oidc.eks.us-east-1.amazonaws.com
/id/AFF2087DBFD0EF4528F23B057B9F1C21
Action:
- sts:AssumeRoleWithWebIdentity
Condition:
# THIS CONDITION IS NECESSARY TO ENSURE THIS
# ROLE CAN ONLY BE USED BY THE PROVIDED SERVICE ACCOUNT,
# AND NOT BY EVERY SERVICE ACCOUNT
SringEquals:
"oidc.eks.us-east-1.amazonaws.com
/id/AFF2087DBFD0EF4528F23B057B9F1C21"
: "system:serviceaccount:your-namespace:service-account-name"
}
}
Policies:
... NO DIFFERENT FOR POLICY CREATION ...
Additionally, recognize in this pattern that since the role itself is not being assumed, but rather directly attached from inside AWS Account A, no additional code changes are necessary. Usage of Full ARNs is not a requirement to change in your code, The management of getting the temporary credentials by request to the API is fully ready to use.
- Setup / Create OIDC Providers - There is a bit of work that you can see from the technical overview in the initial setup of the OIDC provider. The good news is that you only need one provider per EKS cluster/AWS Account. Depending on the proliferation of your accounts you’ll need to ensure that something inside the EKS cluster can periodically execute to create OIDC providers in the necessary accounts. The setup is simple and straightforward with the right information but is made more complex with a lack of support from Cloud Formation, leaving you with the good ol’ API to create them.
- Little Cloud Formation Changes - It is great that I only need one cloud formation stack and template now deployed to the new account. However association to the correct OIDC ARN is crucial, otherwise, frustration is sure to sprout. Having a method for looking this up as part of your deployment and assigning it as a stack parameter might be helpful.
- No Code Changes - Definitely a winner in the no-code changes area. Zero changes for us to make to have this working as if I was deployed into AWS Account A. This was a key requirement for our end goal on developer experience. This makes migration that much easier. That being said, if you find yourself needing to deploy across 3 AWS Accounts, now we are back to discuss some of the previous options. At times, it feels that will be necessary to complete some migrations and future transitions.
- Kube Service Account Association with IAM Roles - It is very important to note the “Condition” applied to the assume role action. Without this condition, it means that you could assign ANY service account created in Kube to have access to the permissions in this role. When building out a multi-purpose cluster you’ll want to look for ways to restrict Service Account creation and validate that roles are not created without a condition limiting it to a certain namespace and/or service account.
- Usage Limits - Unlike previous options, since this role is “attached” from another account directly, all API requests are throttled and tracked based on limits in the AWS Resources Account A (not in the central AWS Account B). WOOO (smile)
Concluding Remarks
Using IAM Roles with Kubernetes Service Accounts is a fantastic option that, with a bit of work, solves the main developer experience requirements we were trying to attain, by mostly making the cross-account capability something the engineers do not have to worry about. That being said, there are many workloads and compute infrastructures not driven in containers or not easily portable to EKS from other platforms. While we can target a simpler, cleaner future with EKS as our centralized compute platform, existing or legacy code migrating to multiple AWS Accounts have options as well, albeit requiring a bit more work and forward planning using role assumption and resource policies. Additionally, consider that depending on your service and logic you may require a hybrid of some or all of these options working together.
Moving forward at SPS Commerce, we are working to simplify the process of our Engineers building for multiple AWS Accounts by using our in-house “BDP Core” deploy service to orchestrate the deployment of Kubernetes Charts alongside automated IAM Role creation that links and associates it to the appropriate Service Account and OIDC Provider all automatically. A story for next time, when it is up and running…
Note: Special callout to thank the efforts of the SPS Commerce Cloud Operations & Site Reliability Engineering teams for their work in evaluating and building proof of concepts of the patterns outlined here.
Travis Gosselin // Dan Cunningham
Reference: http://blog.travisgosselin.com/aws-cross-account-resource…
