Having been a part of a service team for the last couple of years and being responsible for several evolving products with most of them being legacy for the team doesn’t make a developer’s life easy. Sometimes without changes in the everyday routine, the team can end up 100% loaded with the support of current projects without any ability to innovate. We almost faced this issue about a year ago and decided that we needed to do something about it.
A little Context
I should probably start with some facts: A year ago, we had one team, mostly full stack .net Developers responsible for four active projects with different technology stacks: EC2 with .net windows services, EC2/AWS lambdas with python on it, .netcore on AWS lambdas. Getting a new team member with such broad experience would mean 3 to 6 months of onboarding. Not to mention that most people on the market would prefer one tech stack. That far-fetched ideal did not look right. Switching between tasks was painful, and having every person fully involved in all projects became a manager’s nightmare. So, we decided that we needed to change it by implementing some already established community development practices that would untangle this technology stack. Luckily for us, Microsoft had already released .net core 2.2, and it became possible to migrate most of our windows services on .netcore and Linux. Later this decision evolved into .net core 3.0 migration once that was released.
One of the benefits of .net core in general and ASP.net core, in particular, was a new Kestrel server. This simple migration from IIS to Kestrel had a tremendous impact on our performance, but that was expected. The one thing we didn’t expect, though, was that it would become one of the most efficient web servers in general, and migration from Python + Nginx solution to Kestrel + .net core was scheduled right away. Such changes would be a breeze for small APIs, but in our case, it took more than three months to finalize the code migration. One of the reasons for that was the implementation of a new Testing approach, on which I’ll elaborate later.
Slicing our ONION: Moving Towards Vertical Slice Architecture
You might have already guessed that changing and unifying the tech stack wouldn’t help without making changes to the process/architecture. One of the issues we had with one bigger .net project was the number of changes needed when you need to make small changes from a product perspective. So, we decided to slice our ONION and move towards Vertical slice architecture. It might sound like quite an overhead and might lead to code being less reusable, but from what we can see after moving towards this direction and working like that for a year is that it has reduced the time it takes to understand the task and what needs to be done codewise. To achieve that, we implemented some strict folder structures which reduced the number of merge conflicts down to zero. This also allowed multiple team members to work together on the same codebase on different features. The folder structure looks like this.
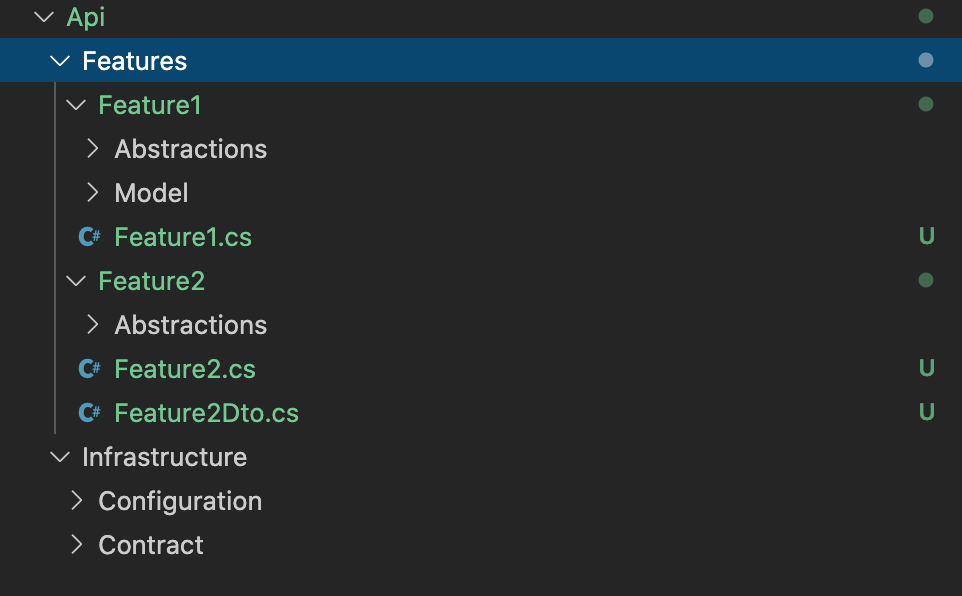
We haven’t restricted ourselves by the strict rules that every Feature/task in Jira should have its feature folder and eventually feature within an application but, we do have a slight correlation between them, so the person working on the feature might not need any additional help in understanding what needs to be done.
Bringing in GitHub Actions & Containerization
Another thing that needed attention was CI/CD tooling. Jenkins, even with pipelines, might be a bit outdated for 2020. Fortunately, in 2020 GitHub Actions was released, so we moved towards using that in all our new projects. Not only did it allow us to have everything in one place but also improved the speed at which we deliver to test and prod environments. For those of you familiar with Drone or Azure DevOps it is pretty much the same, the biggest difference being that you have everything in one place: code, CI/CD, documentation, issues/bug tracking, releases. Format-wise it’s a simple .yml file quite similar to Drone/Azure DO commands. Another thing that helped us a lot in that migration is the way you work with plugins. Just having them in a separate repo where everyone can make necessary changes that will be applied to your pipelines reduces the fuzziness and lack of information on how to create/edit plugins in, for instance, Azure DO or Drone.
Another thing that greatly improved our stability and scalability was containerization. We used to have a ton of simple EC2 servers with Windows on them. It worked great, but scaling was an issue. In cases of inconsistent loads, we would need to spin up a lot of new instances that used to take from 5-20 minutes. To avoid data delays for customers, we were scaling a bit upfront, but it negatively affected our costs. To be able to scale basically to infinity we decided that we needed to get rid of Windows EC2 and substitute it with a container solution. Results were so good that we were able to achieve a tenfold increase in our scaling speed. Right now, it usually takes no more than 30 seconds per container, but the overall resource consumption hasn’t dropped much. We were still pretty low on CPU/memory utilization due to the nature of the service with a lot of 3rd party dependencies like Storage, Queues, DB, etc.
Codebase Changes
So, you might have already guessed, the next iterative thing was codebase changes. We figured out that moving all our services to use async methods whenever possible should optimize resource consumption and increase our performance. After rewriting the codebase to utilize async properly and moving everything to use streams we were able to consume 80-90% of CPU and drastically decrease our RAM consumption. This change alone has led to a fivefold increase in our throughput with the same resources.
Implementing End-to-End Testing
Moving towards container-based services also allowed us to implement a new Testing approach. We used to have integration + unit tests combined with regression tests applied on the test and prod environments, but with an increased amount of microservices, there was also a greater possibility of a failure somewhere in between those services. To reduce such issues, we decided to implement end-to-end testing which should run on every PR. The classic solution would be to implement these in a separate environment like test or dev, but with everything in docker and with the help of localstack we saw that we could avoid the hassle of an additional environment. This change took quite a while to implement, but the results were outstanding. We significantly increased the code quality as well as reducing our time to deliver values. The current hierarchy of our testing looks like this.
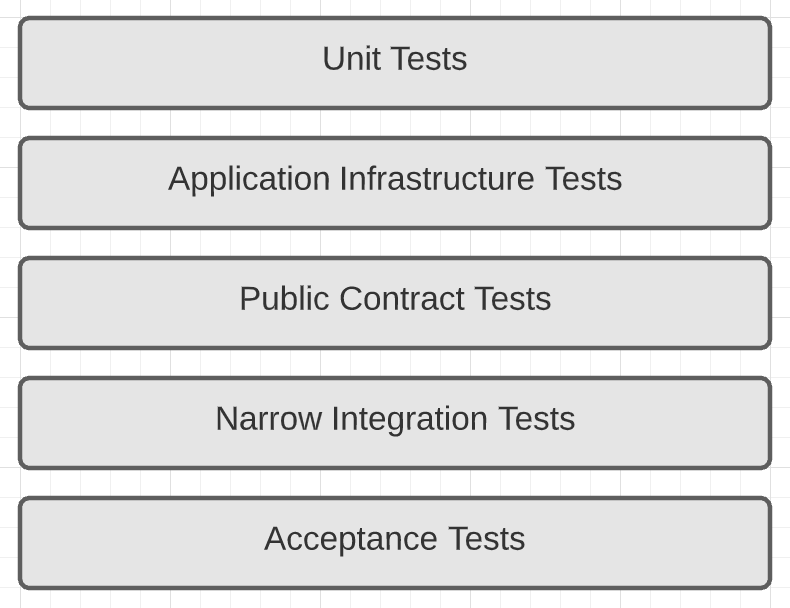
Of course, it is not ideal yet, but, for example, the introduction of Acceptance tests alone has improved our code quality significantly.
What Have These Changes Given Us?
Overall, it does sound like a lot of changes, but what does it mean for the business? The answer would be simple: stability. Changed services have increased their SLOs to 99.99+, the load on the Operations team responsible for these services has decreased, and we have fewer incidents than ever before.
